Integration Testing in Go
Why Write Integration Tests?#
While unit testing ensures that individual units of code work correctly in isolation, the goal of integration testing is to ensure that the application behaviour is correct when those units are wired together.
Note that integration tests concern the integration of units of code within a single application. This is distinct from system or end-to-end tests, in which the integration of the entire software product, with all its constituent applications and services, is under test.

Integration tests typically take longer to write and to run than unit tests. As such, a general rule of thumb is to write integration tests for the code paths that return a successful result. There are much fewer such paths than ones which lead to error, and so the numerous error paths should be covered by your unit tests.
How to Write Integration Tests#
Like unit tests, your integration tests should live alongside the file that contains the (entrypoint to) the code under test. To distinguish from unit tests, I typically use a *_integration_test.go suffix.
The entrypoint should be as high-level in the application as is reasonable. For example, if you have implemented a gRPC handler, your test should live alongside the handler and invoke it directly.
To Mock or Not?#
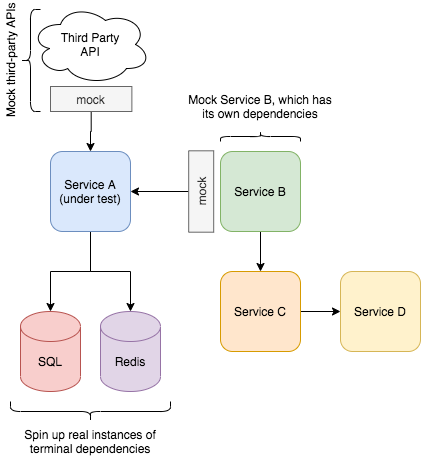
If your application depends on external services, these will need to either be made available for the application to talk to or they will need to be mocked. How do you decide?
Mocking, of course, entails some work. You need to describe what the mocked service should return for every input that is expected - and in an integration test context, that could be a lot of inputs. As such, spinning up an actual copy of the service can make a lot of sense.
However, say your app, service A, depends on the API exposed by service B. You decide to spin up a copy of service B for your integration tests. But what if service B depends on service C? Which in turn needs service D? Pretty soon you’re testing your entire stack, and the integration has become an end-to-end test!
A general rule of thumb is to only spin up dependencies that are themselves standalone, isolated services. Additionally, only spin up dependencies if doing so is cheaper than developing the mock. Examples include databases or caches. Finally, third-party APIs should also be mocked in order to avoid dependency on the stability of services outside of your control (this is the jurisdiction of end-to-end testing), as well as to avoid unnecessary costs in the cases where the APIs are paid-for according to usage.
Testing Against a SQL Database#
It’s a good idea to create a separate database for each of your integration tests. This will allow your tests to execute in parallel without causing data conflicts. Of course, the separate databases can and should all exist in the same Postgres (or other provider) instance, to avoid running multiple copies of your database software.
Spinning Up the Database#
First, spin up an instance of your database. I often have a Makefile target that looks something like:
integ_pg_addr=localhost
integ_pg_port=6543
integ_pg_user=dummy
integ_pg_password=dummy
integ_pg_db=dummy
.PHONY: integ_deps_pg
integ_deps_pg: export POSTGRES_ADDR=$(integ_pg_addr)
integ_deps_pg: export POSTGRES_PORT=$(integ_pg_port)
integ_deps_pg: export POSTGRES_USER=$(integ_pg_user)
integ_deps_pg: export POSTGRES_PASSWORD=$(integ_pg_password)
integ_deps_pg: export POSTGRES_DATABASE=$(integ_pg_db)
integ_deps_pg:
@echo "Spinning up database..."
@-docker kill integ_pg && docker rm integ_pg
@-docker volume create pg_dummy_data
@-docker run -d --shm-size=2048MB -p $(POSTGRES_PORT):5432 --name integ_pg -e POSTGRES_PASSWORD=$POSTGRES_PASSWORD -v $(pg_dummy_data):/var/lib/postgresql/data postgres:12-alpine
@sleep 3
@docker exec -it --user postgres integ_pg psql -U postgres -c "CREATE USER ${POSTGRES_USER} WITH PASSWORD '${POSTGRES_PASSWORD}' CREATEDB;"
@docker exec -it --user postgres integ_pg psql -c "ALTER USER ${POSTGRES_USER} SUPERUSER;"
@docker exec -it --user postgres integ_pg psql -c "CREATE DATABASE ${POSTGRES_DATABASE} OWNER ${POSTGRES_USER};"
The initial ‘main’ database, here called dummy, can then be used to bootstrap creation of a new database for each test, which gets torn down after the test has completed:
// testutil/db.go
var migrationsMu sync.Mutex
var mainDBClient *sql.DB
func init() {
config, err := pgx.ParseConfig(
driver.PSQLBuildQueryString(
viper.GetString(internal.PostgresUserVar),
viper.GetString(internal.PostgresPasswordVar),
viper.GetString(internal.PostgresDatabaseVar),
viper.GetString(internal.PostgresHostVar),
viper.GetInt(internal.PostgresPortVar),
"disable",
) + " client_encoding=UTF8",
)
if err != nil {
panic(err)
}
mainDBClient = stdlib.OpenDB(*config)
}
// NewTestDBClient returns a connection to a test database with the given name. It
// drops the database automatically when the test is finished.
func NewTestDBClient(t testing.TB, name, owner, pw, host string, port int) *sql.DB {
t.Helper()
migrationsMu.Lock()
defer migrationsMu.Unlock()
// use the main database to bootstrap test databases
name = strings.ToLower(name)
_, err := mainDBClient.Exec(fmt.Sprintf("CREATE USER %s WITH PASSWORD '%s' CREATEDB; ALTER USER %s SUPERUSER;", owner, pw, owner))
if err != nil {
// only allow an error indicating that the role already exists
require.Contains(t, err.Error(), fmt.Sprintf(`ERROR: role "%s" already exists (SQLSTATE 42710)`, owner))
}
_, err = mainDBClient.Exec(fmt.Sprintf("CREATE DATABASE %s OWNER %s;", name, owner))
require.NoError(t, err)
// connect to new database
config, err := pgx.ParseConfig(
driver.PSQLBuildQueryString(
owner,
pw,
name,
host,
port,
"disable",
) + " client_encoding=UTF8",
)
require.NoError(t, err)
dbClient := stdlib.OpenDB(*config)
// teardown databases when done
t.Cleanup(func() {
migrationsMu.Lock()
defer migrationsMu.Unlock()
ctx, cancel := context.WithTimeout(context.Background(), time.Second*20)
defer cancel()
dbClient.Close()
_, err = mainDBClient.ExecContext(ctx, "REVOKE CONNECT ON DATABASE "+name+" FROM public; ")
require.NoError(t, err)
_, err = mainDBClient.ExecContext(ctx, `
SELECT pg_terminate_backend(pg_stat_activity.pid) FROM pg_stat_activity
WHERE pg_stat_activity.datname = $1;
`, name)
require.NoError(t, err)
_, err = mainDBClient.ExecContext(ctx, "DROP DATABASE "+name)
require.NoError(t, err)
})
return dbClient
}
Creating the Schema#
To create your database schema, you can use a schema dump of your database created with e.g. pg_dump. If you’re following this migration strategy, your schema is available in ./internal/db/schema.sql.
// CreateDBSchema creates the schema.
func CreateDBSchema(t *testing.T, dbClient *sql.DB) {
sql := db.GetSQL() // a packr *Box
schemaSQL, err := sql.FindString("schema.sql")
_, err = dbClient.Exec(schemaSQL)
require.NoError(t, err)
_, err = dbClient.Exec("SET search_path TO public;")
require.NoError(t, err)
}
Loading Data#
If your test requires your database to be prepopulated with specific data, the best way to do this is to load some test fixtures. These are simple SQL files that insert that data you need. Given a fixture like:
-- ./test/testdata/fixtures/foo.sql
INSERT INTO foo (bar, baz) VALUES ("bar1", "baz1");
INSERT INTO foo (bar, baz) VALUES ("bar2", "baz2");
INSERT INTO foo (bar, baz) VALUES ("bar3", "baz3");
You can load this data into your test database with a function like:
// LoadFixture executes the SQL in the given file against the given database.
func LoadFixture(t *testing.T, db *sql.DB, filename string) {
t.Helper()
file, err := ioutil.ReadFile(path.Join(viper.GetString(internal.TestDataDirVar), "fixtures", filename))
require.NoError(t, err)
requests := strings.Split(string(file), ";\n")
for _, request := range requests {
_, err := db.Exec(request)
require.NoError(t, err, filename)
}
}
Putting this all together, your integration test setup might look something like:
func TestFoo(t *testing.T) {
t.Parallel()
ctx := context.Background()
name := strings.Join(strings.Split(t.Name(), "/"), "_")
dbClient := testutil.NewDBClient(t,
name,
viper.GetString(internal.PostgresUserVar),
viper.GetString(internal.PostgresPasswordVar),
viper.GetString(internal.PostgresHostVar),
viper.GetInt(internal.PostgresPortVar),
)
testutil.CreateDBSchema(t, dbClient)
testutil.LoadFixture(t, dbClient, "foo.sql")
// Now do your test!
}
Testing Against AWS#
Often, your application may rely on various services made available by your cloud provider. One option in this case is to mock the library you use to interact with the cloud provider.
If you’re using AWS, another option I’ve successfully used in the past is LocalStack. LocalStack lets you spin up a local copy of the AWS stack with which your application integration tests can interact.
The easiest way to get started with LocalStack is using Docker. First, copy the Docker Compose file into your third_party folder. Then you can spin up LocalStack using docker-compose and use the AWS CLI to perform any setup required (like creating S3 buckets):
.PHONY: integ_deps_localstack
integ_deps_localstack:
@-docker kill localstack_main
@TMPDIR=/private$(TMPDIR) docker-compose -f ./third_party/localstack/docker-compose-localstack.yml up -d
@echo "Waiting 20s for LocalStack..." && sleep 20
@eval $(aws ecr get-login --no-include-email)
@source ./scripts/env.sh $(env) && AWS_ACCESS_KEY_ID=dummy AWS_SECRET_ACCESS_KEY=dummy aws --endpoint-url=http://localhost:4566 s3 mb s3://bucket-foo
Conclusion#
Writing integration tests is an essential part of ensuring your application components work correctly together. Done correctly, they will give you confidence that future changes do not break existing functionality and that your application is robust, stable and correct.
Do you have other integration test tips and tricks? Hit me up on Twitter!